Rank by OSM – Fahrradinfrastruktur in OSM vs ADFC
Jan Gemeinholzer
Dieser Beitrag behandelt die Umsetzung einer Projektidee zur Frage: Wie umfassend und konsistent wird Fahrrad-Infrastruktur in Openstreetmap gemappt?
Erlangen, Münster, Nürnberg – Abbildungen fahrradbezogener Infrastruktur im OpenStreetMap-Datensatz im Abgleich mit den Ergebnissen des ADFC-Fahrradklimatests 2014
1 tags und OSM versus „die echte Welt“
„OpenStreetMap represents physical features on the ground (e.g., roads or buildings) using tags attached to its basic data structures (its nodes, ways, and relations). Each tag describes a geographic attribute of the feature being shown by that specific node, way or relation.“ (OSM-Wiki-Artikel „Map Features“, aufgerufen am 10.03.2015)
So lautet der Einleitungssatz zum Wiki-Artikel „Map Features“, der die Grundelemente der OpenStreetMap-Weltkarte erklärt. Ein zentraler Bestandteil der Struktur des OSM-Datensatzes sind demnach die sogenannten tags. Tags sind Kombinationen aus keys und values (Schlüsseln und Werten), die die verschiedenen Punkt- (=nodes) und Linienelemente (=ways) in der Datenbank, sowie relationale Verknüpfungen dieser beiden Eintragstypen (=relations) mit Metainformationen anreichern wie bspw. einem Eintrag zum Namen des Objektes, einer Information über die Postleitzahl eines Gebietes, oder einer Angabe der Höchstgeschwindigkeit auf einer Straße. Gehen wir also einmal davon aus, dass wir es beim OpenStreetMap-Projekt mehrheitlich mit „wahrheitsgemäßen“ Kartierungen zu tun haben und nehmen wir ferner an, dass auch die Detailinformationen in Form der tags von den usern so „korrekt“ wie möglich eingetragen wurden – dann könnten Analysen und Interpretationen der tags im OSM-Datensatz gewisse Rückschlüsse auf eine wirkliche Situation in der realen Welt zulassen, die das OSM-Projekt abbilden möchte (siehe oben). Es muss jedoch stets bedacht werden, dass ich hier in erster Linie den digitalen OSM-Datensatz und nicht „die wirkliche Situation“ in der physisch-materiellen Welt beforschen möchte. Es geht darum, die im Seminar Geodatenbanken-Analysen kennengelernten, explorativen Methoden zur Analyse von Geodatenbanken in einem möglichst sinnstiftenden Zusammenhang anzuwenden.
Nun zu meiner Projektidee: Der Allgemeine Deutsche Fahrradclub (ADFC) e. V. evaluiert in unregelmäßigen Abständen, zuletzt im Jahr 2014, das „Fahrradklima“ in deutschen Städten. Im aktuellen Städteranking belegte meine Heimatstadt Nürnberg mit einem Gesamtindex von 4,01 Platz Nr. 26 von insgesamt 39 bewerteten Städten in der Stadtgrößengruppe >200.000 Einwohner. Klarer Sieger des Rankings ist Münster mit einem Gesamtindex von 2,50. Auf Platz 1 von insgesamt 37 Städten im Ranking der Stadtgrößengruppe 100.000-200.000 Einwohner steht das schon lange als Fahrradstadt geltende Erlangen mit einem Gesamtindex von 3,28[i]. Ich möchte diese drei Städte herauspicken und untersuchen, ob und inwiefern der OSM-Datensatz die Ergebnisse des aktuellen ADFC-Fahrradklimatests widerspiegeln kann. Das Ziel der Projektarbeit ist es, die Datenbasis für ein alternatives Ranking dieser drei Städte zu schaffen, die auf Abbildungen fahrradbezogenener Infrastrukturelemente in OSM und einer Bewertung des Engagements der OSM-Community im Gebiet der drei untersuchten Städte beruht.
2 Die Suche nach Fahrradinfrastruktur in OSM
Problem dabei: Der OpenStreetMap-Datensatz ist mittlerweile riesig und in seiner Gesamtheit für Normalsterbliche schwer handhab- oder analysierbar. Aus diesem Grund und auch weil die Mehrzahl der Indikatoren des ADFC-Tests in OSM bisher nicht abgebildet wurden bzw. überhaupt nicht abbildbar sind, scheint es mir notwendig und sinnvoll, die Untersuchung nach der Auswahl der drei Städte anhand der Evaluationskriterien im ADFC-Fragebogen auf drei Bereiche weiter zu fokussieren:
-Sicherheit beim Radfahren (Variable F14: Hindernisse auf Radwegen)
-Komfort beim Radfahren (Variablen F19: Belag und Zustand der Radwege, F20: Abstellmöglichkeiten)
-Infrastruktur und Radverkehrsnetz (Variablen F23: Stadtzentrum ist mit dem Fahrrad gut erreichbar, F25: Einbahnstraßen sind für Radfahrer/innen in Gegenrichtung befahrbar, F27: touristische Fahrradvermietung)
Den ausgewählten ADFC-Variablen (Tabellenblatt: ADFC_Variablen) ordne ich später bestimmte tags bzw. Abfragen zu (F**_JG), mit denen in PostgreSQL Ergebnistabellen generiert werden. Die entsprechenden Zuordnungen und alle durchgeführten Arbeitsschritte in SQL finden sich in der Dokumentation. Über den „Vergleich“ mit den ADFC-Variablen hinaus ist es auch interessant, mehr über die user und die Verteilung der tags in einem Gebiet zu erfahren. Spezifische räumliche/zeitliche und tag-orientierte Abfragen können weitere Einblicke ermöglichen:
-JG1: user im Untersuchungsgebiet
-JG2: Fahrradläden im Untersuchungsgebiet
-JG3: Fahrradinfrastrukturelemente im Untersuchungsgebiet
Mit queries, die ich hier aus Platzgründen nicht explizit aufführen kann, können gewisse Aussagen über die user-Struktur getroffen werden, was dann weitere Spekulationen ermöglicht, bspw. zu Tätigkeitsmustern besonders aktiver oder passiver user. Ein Vergleich der Anzahl der user mit der Bevölkerungszahl der Städte (Zensusdaten) und der Fläche des jeweiligen Untersuchungsgebietes, sowie die Analyse der maximalen und durchschnittlichen Versionsnummern der Objekte können z. B. verdeutlichen, wie engagiert die OSM-Community in einem Areal ist; Oder sie können zeigen, wie das Verhältnis der Anzahl bestimmter Objekte in OSM zur Größe der Stadtbevölkerung ist (z.B. Fahrradläden/Einwohner). Zentrale Herausforderung ist es nun eigentlich nur noch, die richtigen tags (d. h. immer: passende key-value-Kombinationen) für die Untersuchungsobjekte herauszufinden. Ein weiterer zeitintensiver Arbeitsschritt ist die Ausformulierung der SQL-Abfragen (PostgreSQL 9.4 und Postgis 2.1.5).
-> Hier geht’s zur Dokumentation
-> Hier geht’s zur Ergebnis-Tabelle
3 Analysen, Interpretationen und Ergebnisse
Die Ergebnistabellen können aus PostgreSQL problemlos als Layer in QGIS oder andere GIS-Programme importiert werden, um bspw. Karten zu gestalten oder weitere Berechnungen anzustellen. Grafische Darstellungen der abgefragten Daten sind sinnvoll und zur Kontrolle empfehlenswert, weil man meistens schon bald erkennt, wenn etwas schief gelaufen ist – und das passiert im tag-Dschungel der OSM-Welt schnell und häufig.
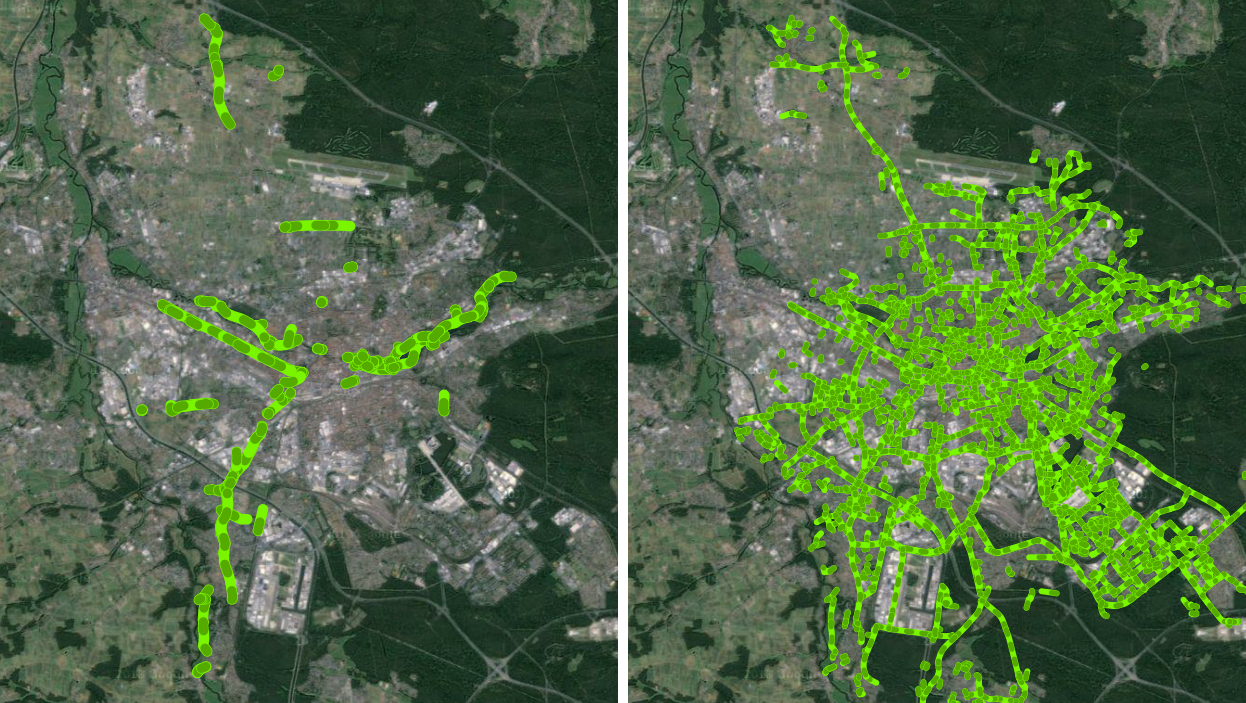
In Abbildung 1 sind links alle Fahrradwege zu sehen, die den key „smoothness“ in Kombination mit einem der von mir als aussagekräftig identifizierten values besitzen (siehe Dokumentation). Im Kartenausschnitt rechts sind zum Vergleich alle als Fahrradweg klassifizierten ways im Untersuchungsgebiet Nürnberg dargestellt (Screenshots aus QGIS).
Ich möchte anhand des Beispiels aus Abb. 1 hier noch kurz auf die Entwicklung der Abfragen eingehen: Es scheint offensichtlich, dass die anfangs gewählten smoothness-tags (zumindest in Nürnberg) nicht besonders gut geeignet waren, um die ADFC-Variable F19 (Belag und Zustand der Radwege) in OSM „wiederzufinden“ – denn sie wurden schlichtweg zu selten oder vor allem in falschen Kombinationen vergeben. Das heißt: Nicht den aktuellen Kartier-Richtlinien der OSM-Community entsprechend; Um ein befriedigenderes Ergebnis zu erhalten, musste diese Abfrage dann also bspw. noch um verschiedene tags mit dem key „surface“ erweitert werden. Ich bin bei allen anderen Abfragen ähnlich vorgegangen. Nach der Überprüfung und Verfeinerung der zahlreichen SQL-Queries werden diese „ultimativ“ durchgeführt und die Ergebnisse wiederum in einzelne Tabellen geschrieben.
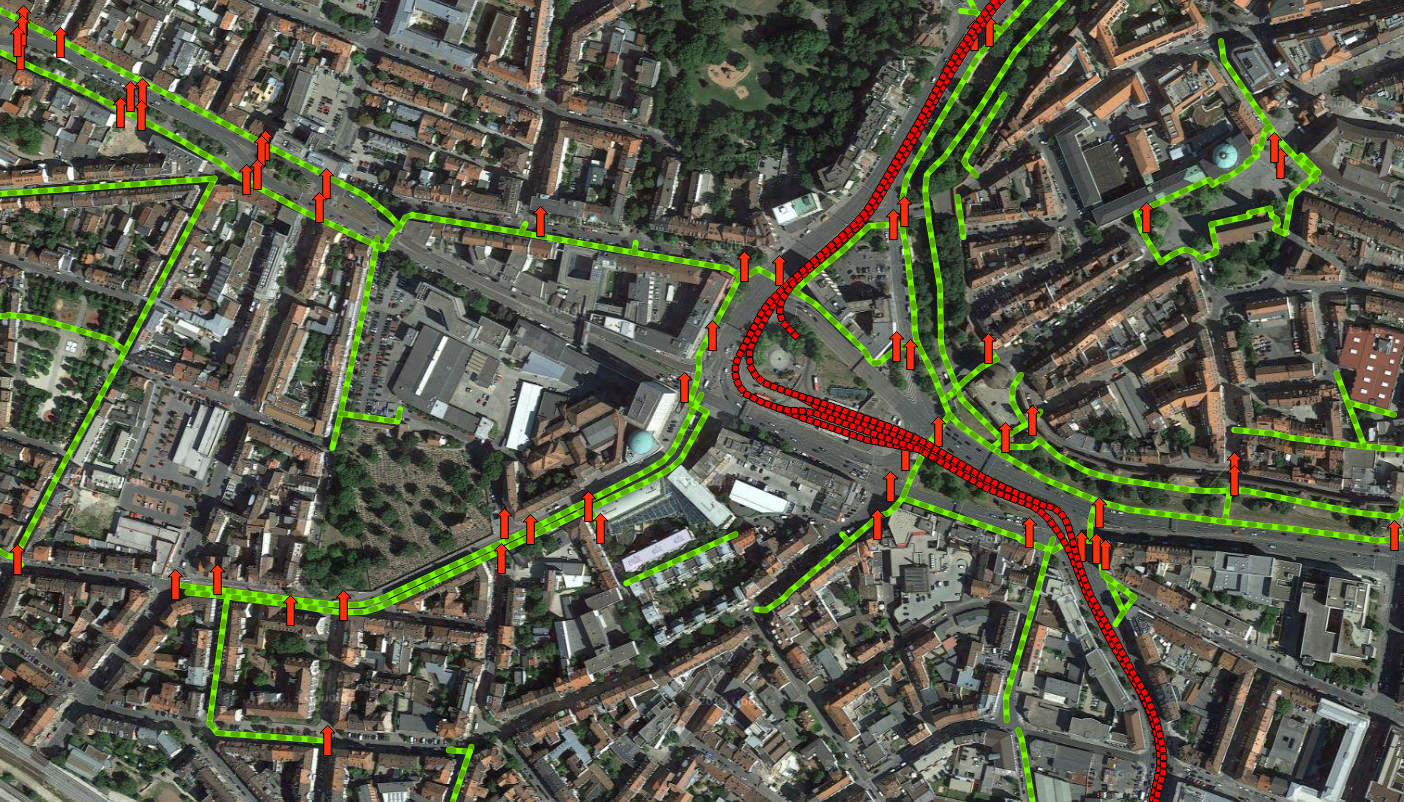
Abbildung 2: Im Bildausschnitt des Nürnberger Plärrers sind jene als Hindernis definierten Objekte zu sehen (nodes=rote Pfeile, ways=rote gestrichelte Linien), die im Umkreis von 15m zu einem als Fahrradweg (grüne Linien) definierten Objekt liegen.
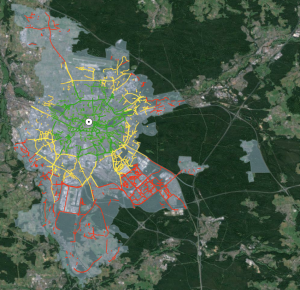
Abbildung 3: Das Nürnberger Untersuchungsgebiet (hellblau) mit allen Fahrradwegen, die in einem Umkreis von 3 km (grün), 5 km (gelb), oder mehr als 5 km (rot) vom Stadtzentrum (weißer Punkt) verlaufen.
Abbildung 4: Fahrradwege im 3-km-Radius länger als 300m (grün), im 5-km-Radius länger als 500m (gelb).

Der nächste Schritt ist, die Ergebnisse (Visualisierungen siehe Abbildungen 2, 3 und 4) in eine „übersichtliche“ Tabellenkalkulation zu übertragen, wofür ich Microsoft Excel nutze. Danach geht es darum, das Ganze noch näher zu betrachten und dabei die verschiedenen Probleme und Implikationen aus der Phase der Abfragenentwicklung zu bedenken, um die Zahlen im Hinblick auf die Projektfragestellung interpretieren zu können. Die hier präsentierten Ergebnistabellen sind also mit großer Vorsicht und nur im Kontext dieser Projektarbeit und des Geodatenbanken-Analysen-Seminars zu genießen:
Meine Messergebnisse zeigen im Gesamtdurchschnitt eine erstaunlich gute Übereinstimmung mit den Indizes des ADFC-Fahrradklimatests (vgl. Tabelle 1). Wie ich bei der Berechnung der einzelnen Faktoren genau vorgegangen bin, wie ich sie gewichtet habe und welche Abfragen letztendlich in mein Ergebnis mit eingeflossen sind, erschließt sich aus der Excel-Tabelle (->Formeln) und der Dokumentation.
Es wurde darauf geachtet, möglichst „realistische“ Indikatoren aus den Abfrage-Ergebnissen zu bilden. Zum Teil gibt es erhebliche Unterschiede in der Anzahl der Datensätze im Vergleich von nodes und ways (ich habe alle Abfragen auf diese beiden Elementtypen beschränkt), so mussten bspw. immer erst Summen gebildet werden, um die Gesamtzahl der untersuchten Objekte zu erfassen. In drei Untersuchungskategorien gab es direkte Übereinstimmungen in der Rangfolge der Messwerte mit der Rangfolge der ADFC-Variablen (Abstellmöglichkeiten, für Radfahrer/innen freigegebene Einbahnstraßen, touristische Fahrradvermietung). Das heißt, hier haben meine Abfragen die These direkt gestützt, dass „echte“ Verhältnisse, die in den Messergebnissen des ADFC-Fahrradklimatests repräsentiert werden sollen, tatsächlich auch in OSM abgebildet werden (vgl. Tabelle 2). Während der ADFC aus seinen Indikatoren für jede Stadt eine „echte“ Gesamt-Schulnote errechnet (z. B. 2,3), habe ich lediglich die Ziffern 1-3 vergeben, um die drei untersuchten Städte zu bewerten (1 = 1. Platz, 2 = 2. Platz, 3 = 3.Platz).

Tabelle 1: Endergebnisse JG sind im Gegensatz zu den ADFC-Indizes NICHT als Schulnoten zu verstehen, da sie Durchschnittswerte aus der Rangzahl (1-3) sind.
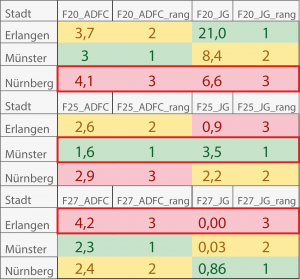
Tabelle 2: Direkte Übereinstimmungen (rot umrandet) in der Rangfolge der Städte basierend auf meinen Messergebnissen im Abgleich mit der Rangfolge der Städte aus den ADFC-Indikatoren (Abstellmöglichkeiten, für Radfahrer/innen freigegebene Einbahnstraßen, touristische Fahrradvermietung).
Die Diagramme unten zeigen einzelne Untersuchungsergebnisse, die nicht zwingend mit in die Gesamtbewertung eingegangen sein müssen, aber auch interessant sind, wenn es um die Untersuchung von Fahrradinfrastruktur in OpenStreetMap oder das Engagement der Community in den Untersuchungsgebieten geht:
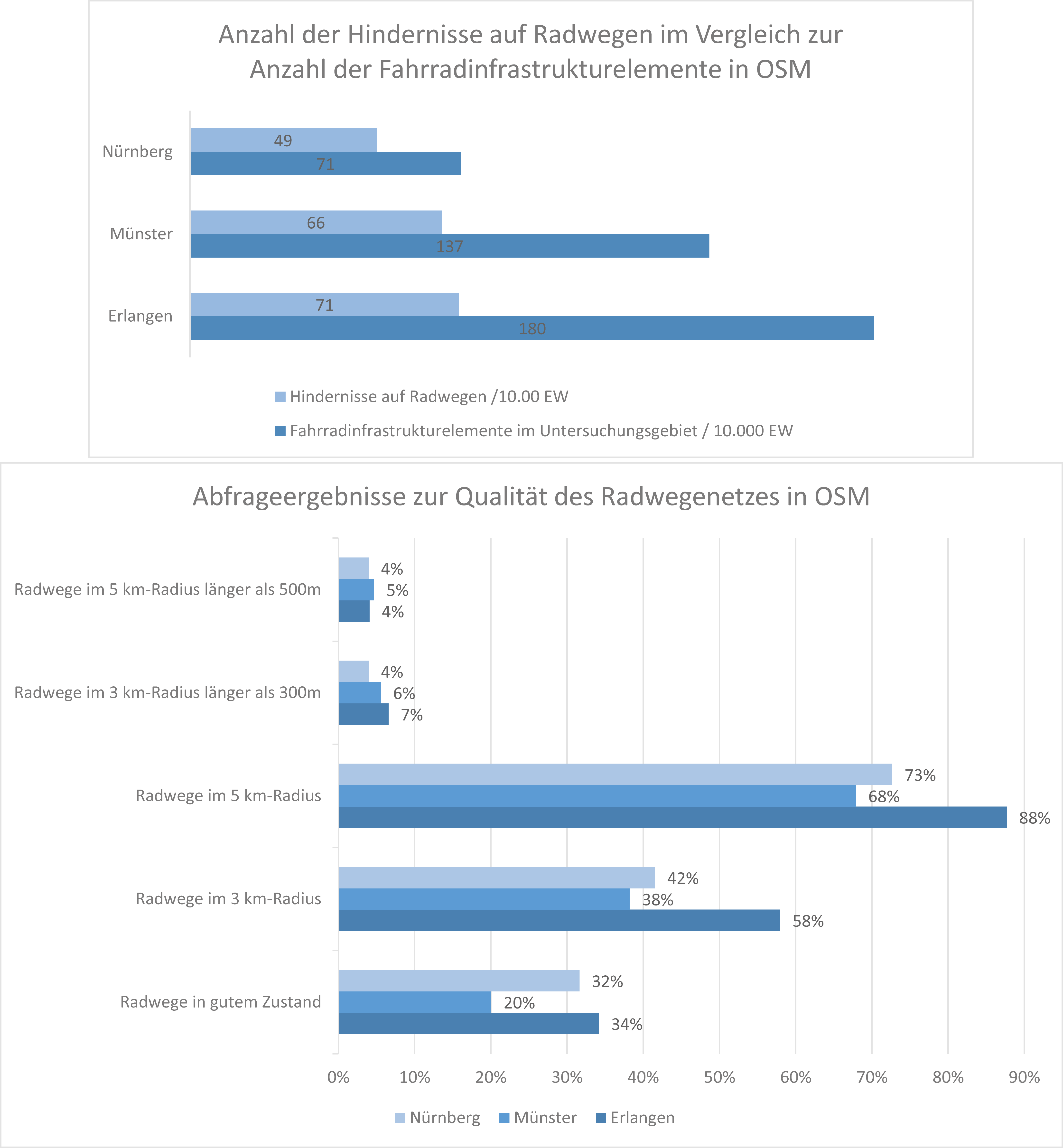
Es fällt auf, dass die Anzahl der von mir in OSM als „Fahrradinfrastrukturelemente“ definierten Objekte in der Regel rund doppelt so hoch ist, wie die Anzahl der Objekte, die meine Abfragen als Hindernisse auf Radwegen identifiziert haben. Oder, dass nur rund ein Drittel aller als Fahrradweg getaggten Objekte in OSM eine zusätzliche, eindeutige Information über gute Befahrbarkeit haben.
Im Schnitt sind drei Viertel der Fahrradwege in einem Umkreis von 5 km um das Stadtzentrum gelegen. Ob die Distanz zum Stadtzentrums-node und die Länge der linestring-Geometrien der einzelnen ways geeignete Maße für die Erreichbarkeit des Stadtzentrums darstellen, ist streitbar. Wie gut eine Abfrage „trifft“ hängt maßgeblich von der Auswahl der zu suchenden tags ab und davon, ob diese tags im jeweiligen Untersuchungsgebiet von den usern überhaupt vergeben werden.
4 Alles OSM oder was?
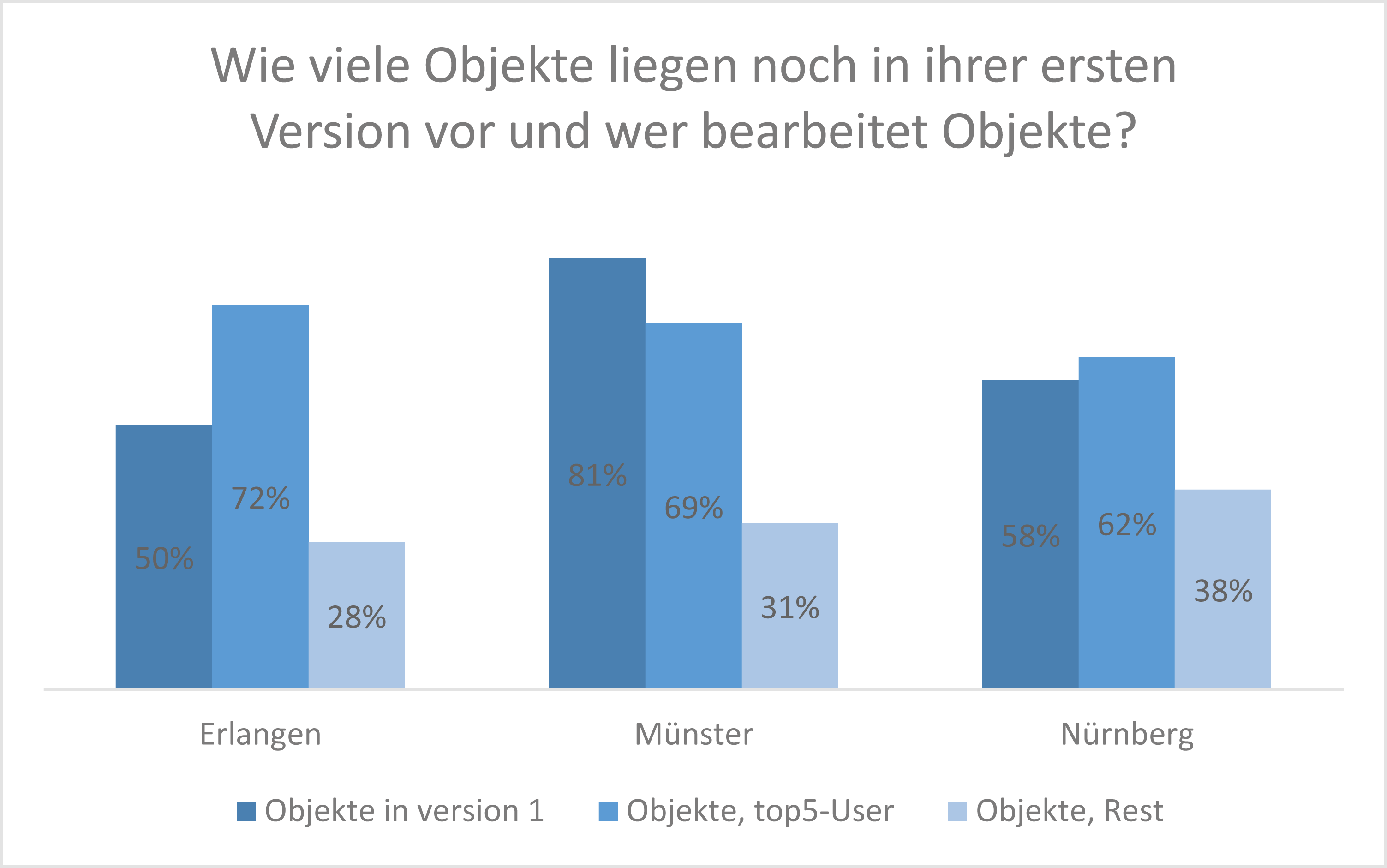
Einerseits zeigt sich, dass durchschnittlich rund zwei Drittel der untersuchten Objekte zuletzt von allein fünf usern bearbeitet wurden, andererseits, dass die „Aktualität“ der Daten in Nürnberg und Erlangen wohl höher ist, als in Münster – vorausgesetzt, die Anzahl der Objekte, die noch in ihrer ersten Version vorliegen, kann überhaupt als Indikator für die Aktualität der Daten herangezogen werden. Die durchschnittliche Versionsnummer aller untersuchten Objekte in den Untersuchungsgebieten beträgt zum Zeitpunkt der Durchführung des Projekts 2,0217…, also 2. Das heißt, jedes Objekt wurde im Durchschnitt erst ein Mal bearbeitet, nachdem es in den OSM-Datensatz aufgenommen wurde. Erlangen und Nürnberg haben mit rund 55% einen markant geringen Anteil an version 1-Objekten im Vergleich zu Münster mit 81%. Vergleicht man die durchschnittlichen Versionsnummern der Objekte, die von den jeweiligen top5-usern (nodes/ways) bearbeitet wurden mit denen, die von den restlichen usern bearbeitet wurden, so zeigt sich, dass die top5-user eher Objekte mit einer niedrigeren Versionsnummer bearbeiten, als der Rest. Das könnte wiederum heißen, dass die top-user in einem Gebiet eher neue Objekte anlegen, oder neu angelegte Objekte einmalig korrigieren (denn das bringt u. a. auch einen edit für die Statistik), anstatt bereits „etablierte“ Objekte mit einer höheren Versionsnummer erneut anzupacken oder zu überprüfen. Und das ist nur eine mögliche Interpretation dieser Zahlen. Hier wäre bspw. eine Anwendung von Methoden des data mining hilfreich, um noch bessere Indikatoren aus den Messwerten zu bilden und aussagekräftigere Ergebnisse zu generieren, als ich es im Rahmen dieser Projektarbeit durchführen kann.
Meine Ergebnisse deuten summa summarum erstaunlicherweise darauf hin, dass in OSM ein relativ „wahrheitsgemäßes“ Abbild der Radverkehrsinfrastruktur in den untersuchten Städten geschaffen wird und, dass sich die vom ADFC evaluierten Verhältnisse (in Teilen, festgemacht an materieller Infrastruktur) auch in OSM wiederfinden. Vorausgesetzt, man sucht nach den „richtigen“ tags und die Daten sind „richtig“ getaggt. Bei diesen Analysen und Interpretationen sollte aber stets bedacht werden, dass sich in den Daten aus dem OpenStreetMap-Projekt immer auch die Realitäten der user widerspiegeln, genauso wie sich in den anschließenden Interpretationen auch die Sichtweisen der Interpretierenden einschreiben. Dennoch, oder gerade deswegen, können räumliche, zeitliche und tag-orientierte Analysen des OSM-Datensatzes sehr aufschlussreich und interessant sein, was ich hoffe, in diesem Projektbericht gezeigt zu haben. Für Kritik, Anregungen und Fragen zum Thema stehe ich gerne zur Verfügung!
[i] Gesamt-Ergebnis-Tabelle des ADFC-Fahrradklimatests 2014. Enthält auch eine Beschreibung der erhobenen ADFC-Variablen (S.13).
-> Hier geht’s zur Dokumentation
-> Hier geht’s zur Ergebnis-Tabelle
Verfasser: Jan Gemeinholzer, jan.gemeinholzer@fau.de